Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
Adaptive Layer Splitting for Wireless LLM Inference in Edge Computing ...
Quantum LLM Inference Transformation | PDF | Quantum Computing | Computing
EdgeShard: Efficient LLM Inference via Collaborative Edge Computing - 智 ...
[论文评述] SLICE: SLO-Driven Scheduling for LLM Inference on Edge Computing ...
SAIL: New Computing Architecture Boosts LLM Inference Speed by 19.9x ...
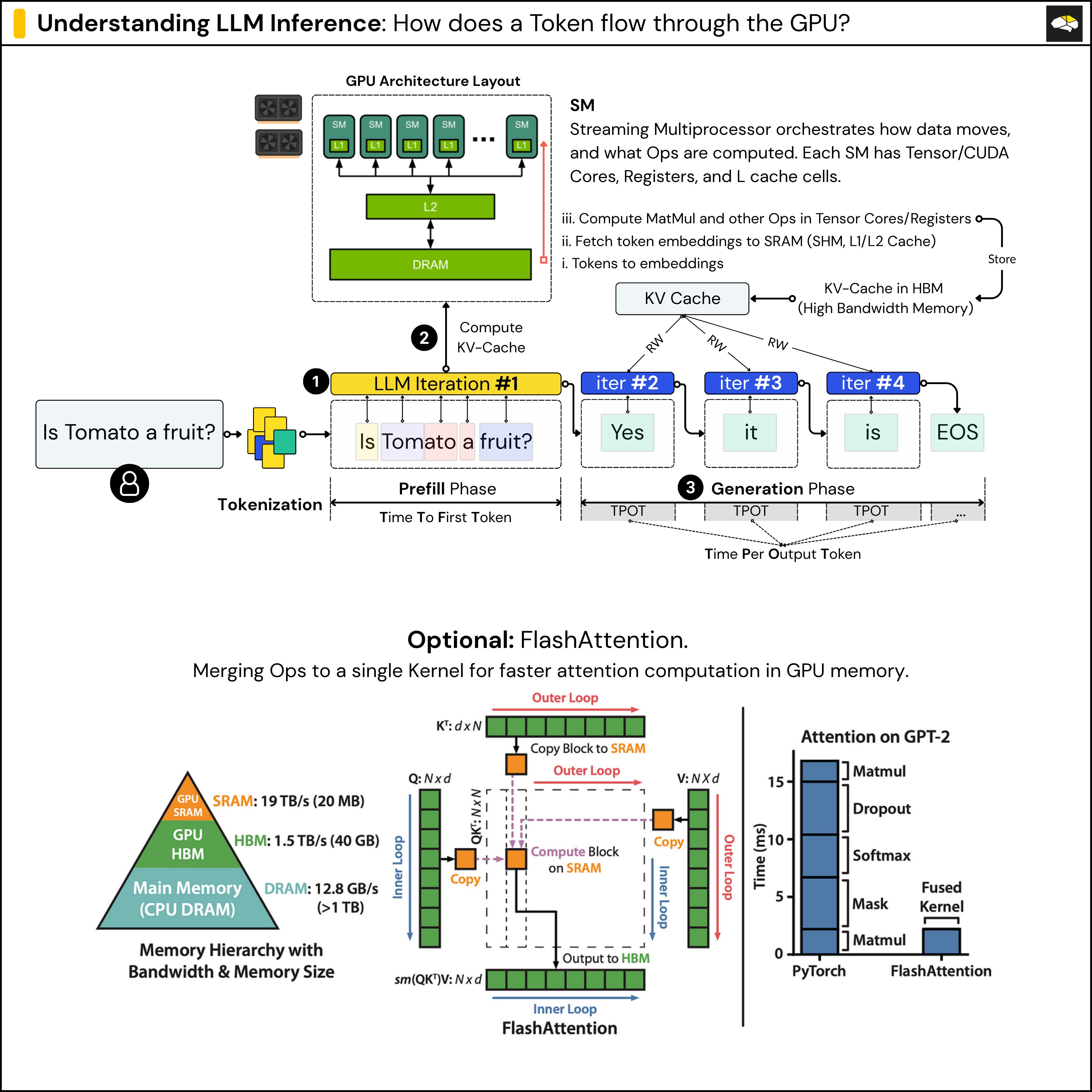
Understanding LLM Inference - by Alex Razvant
[논문 리뷰] Adaptive Layer Splitting for Wireless LLM Inference in Edge ...
A Survey of LLM Inference Systems | alphaXiv
The State of LLM Reasoning Model Inference
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
LLM Inference Stages Diagram | Stable Diffusion Online
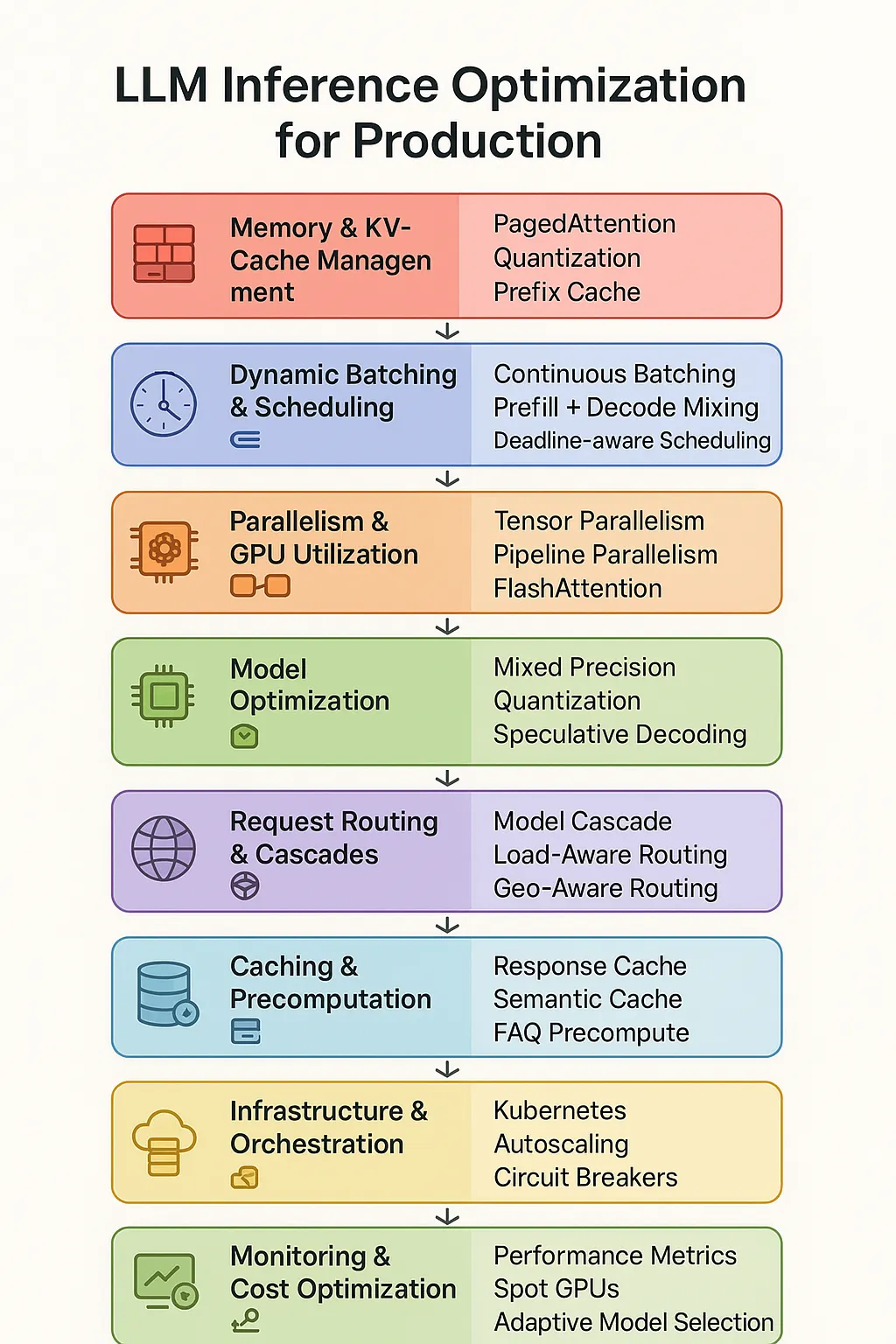
LLM Inference Optimization Overview - From Data to System Architecture
Illustration of the proposed method. (a) LLM inference comprises two ...
LLM Inference - Hw-Sw Optimizations
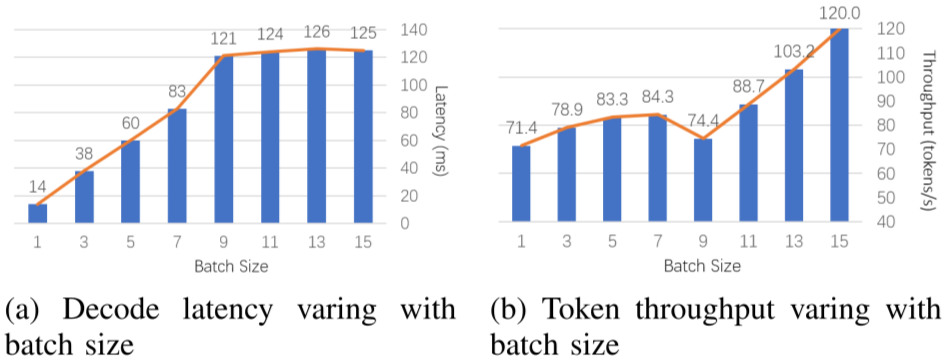
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
LLM Inference Essentials
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
LLM Inference Optimization for NLP Applications
LLM Inference Benchmarking: Performance Tuning with TensorRT-LLM ...
VLLM: Using PagedAttention To Optimize LLM Inference and Serving ...
Architecture and System Co-Design for High-performance LLM Inference ...
LLM Inference Unveiled: Survey and Roofline Model Insights | PDF ...
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
[论文评述] DILEMMA: Joint LLM Quantization and Distributed LLM Inference ...
Exploring Hybrid CPU/GPU LLM Inference | Puget Systems
What Is LLM Inference? Batch Inference In LLM Inference
A guide to LLM inference and performance | Baseten Blog
LLM Inference - Consumer GPU performance | Puget Systems
LLM Inference Workload Insights | PDF | Cache (Computing) | Graphics ...
What is LLM inference? | LLM Inference Handbook
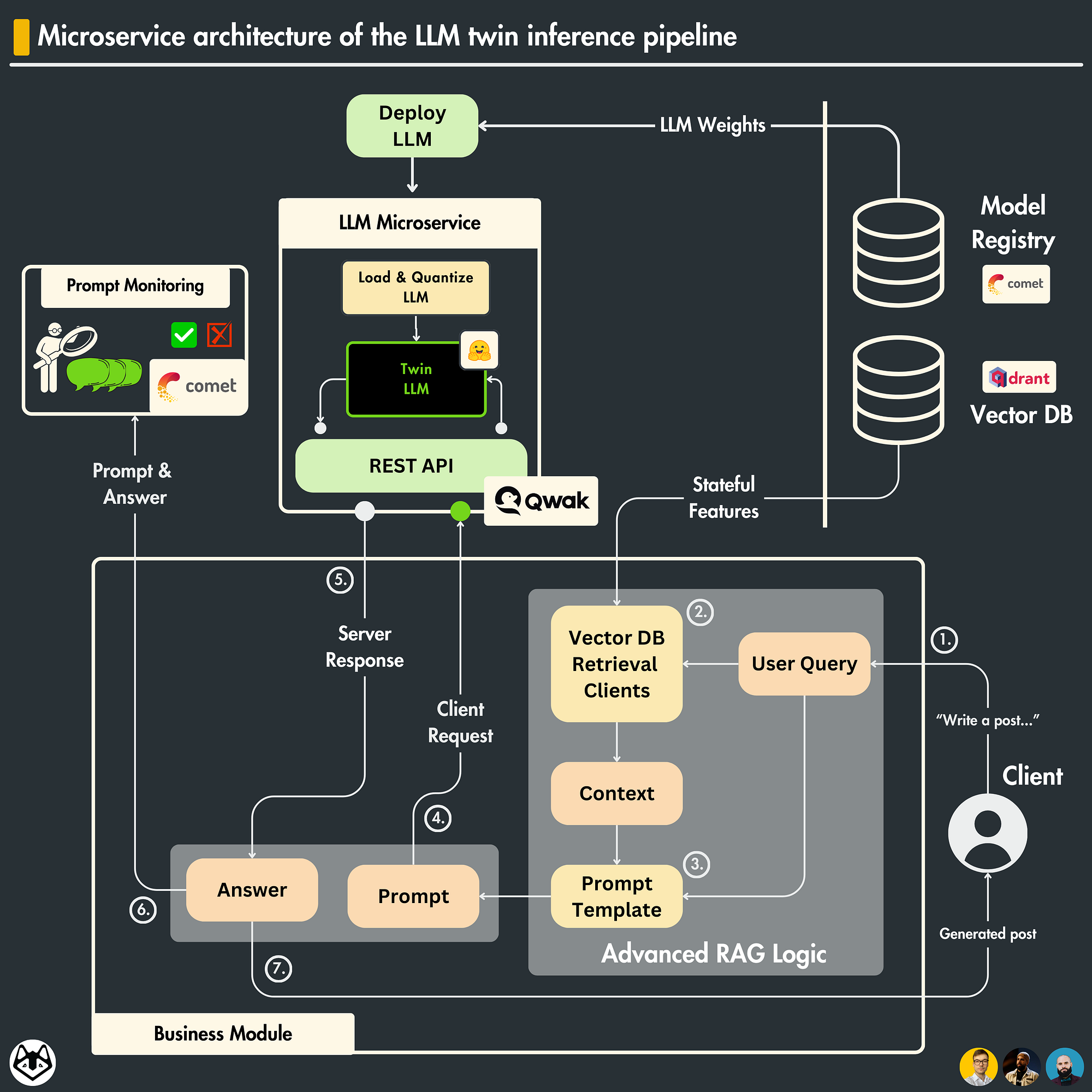
How to Architect Scalable LLM & RAG Inference Pipelines
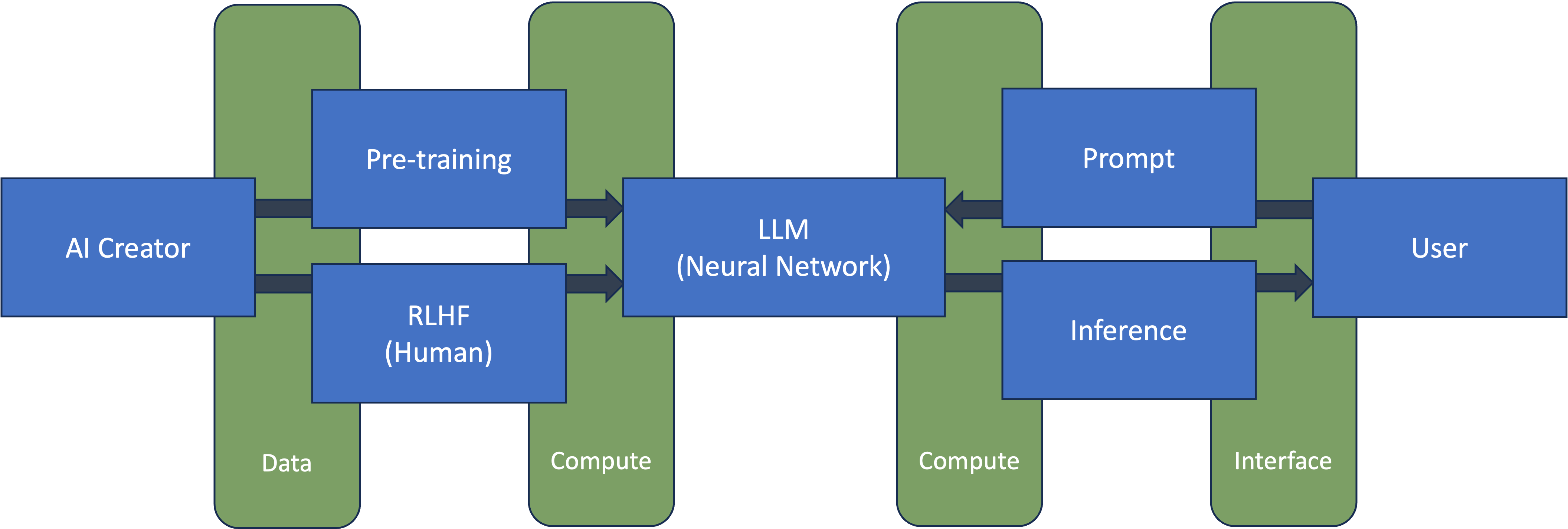
How LLM really works: From Training to Talking – The Power of Inference
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
A Survey of Efficient LLM Inference Serving | PDF | Scheduling ...
Understanding the LLM Inference Workload: Key Insights
LLM Inference - NVIDIA RTX GPU Performance | Puget Systems
How to Run Local Inference Server for LLM in Windows - YouTube
Best LLM Inference Engine? TensorRT vs vLLM vs LMDeploy vs MLC-LLM | by ...
LLM Inference Archives | Uplatz Blog
Local LLM Inference and Fine-Tuning | PDF | Graphics Processing Unit ...
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
Speeding up LLM Inference With TensorRT-LLM S62031 | GTC 2024 | NVIDIA ...
Overview of an Example LLM Inference Setup - YouTube
LLM Inference Benchmarking Guide: NVIDIA GenAI-Perf and NIM | NVIDIA ...
LLM Inference Benchmarking: Fundamental Concepts | NVIDIA Technical Blog
Scaling LLM inference with Ray and vLLM
Illustration of the privacy-preserving LLM inference. The LLM inference ...
(PDF) Improving the inference performance of LLM with code
LLM Inference
On-Device LLM Inference at 600 Tokens/Sec.: All Open Source - YouTube
Figure 3 from Efficient LLM inference solution on Intel GPU | Semantic ...
Free Video: Large Scale Distributed LLM Inference with LLM-D and ...
Nvidia's H100 NVL Inference Platform is Optimized for LLM Deployments
[PDF] LLM Inference Serving: Survey of Recent Advances and ...
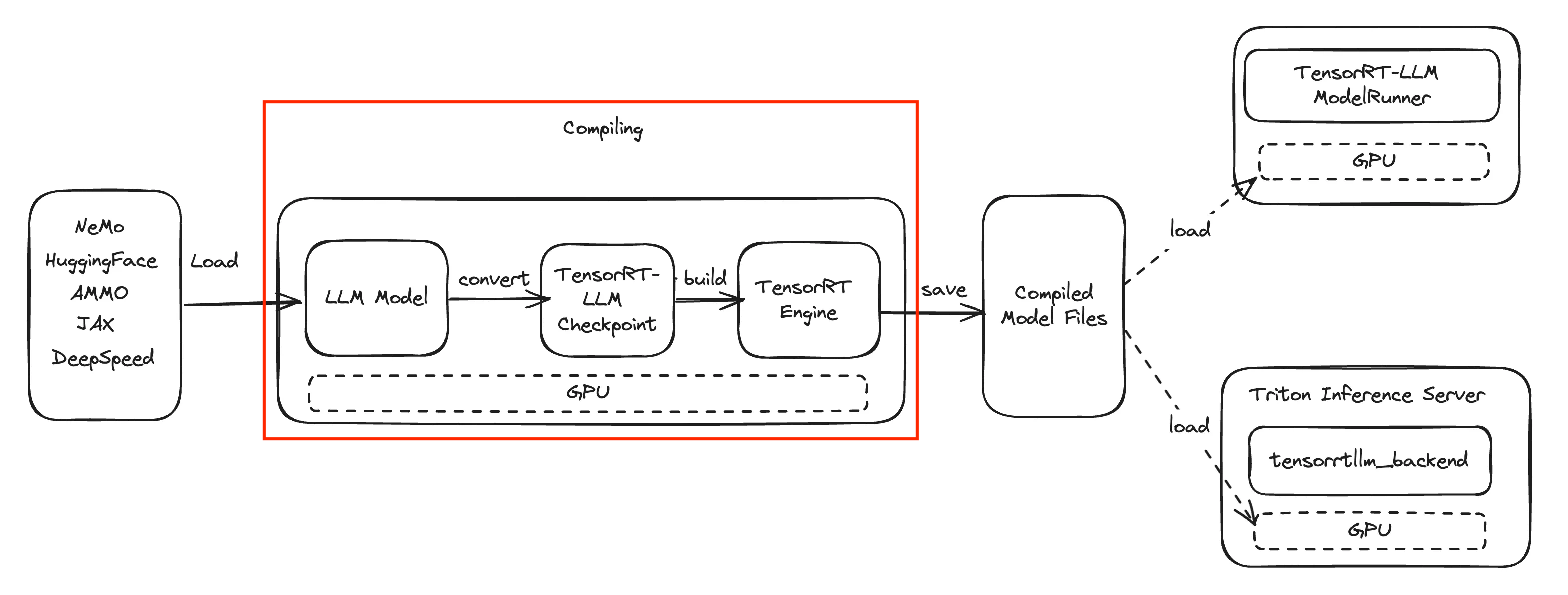
Compiling a LLM for High Performance Inference - Rafay Product ...
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
Improving LLM inference speeds on CPUs with model quantization | UnfoldAI
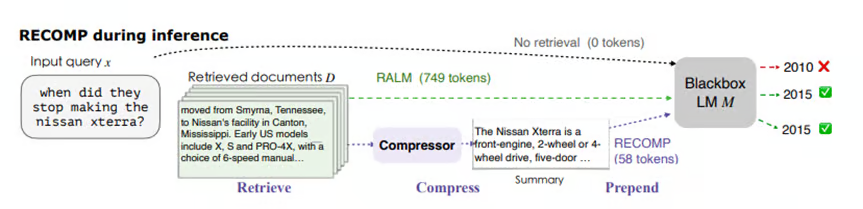
LLM Inference — Optimizing the KV Cache for High-Throughput, Long ...
Efficient LLM inference on CPUs : r/LocalLLaMA
Learn LLM Inference Optimization with #TowardsAI | Towards AI, Inc ...
Scale LLM Inference with Multi-Node Infrastructure — ROCm Blogs
LLM Inference Sizing: Benchmarking End-to-End Inference Systems S62797 ...
Top LLM Inference Providers Compared - GPT-OSS-120B
Splitwise improves GPU usage by splitting LLM inference phases ...
Kubernetes-Based LLM Inference Architectures: An Overview | Yuchen ...
(PDF) Scalable Inference Systems for Real-Time LLM Integration
S62797 - LLM Inference Sizing - Benchmarking End-to-End Inference ...
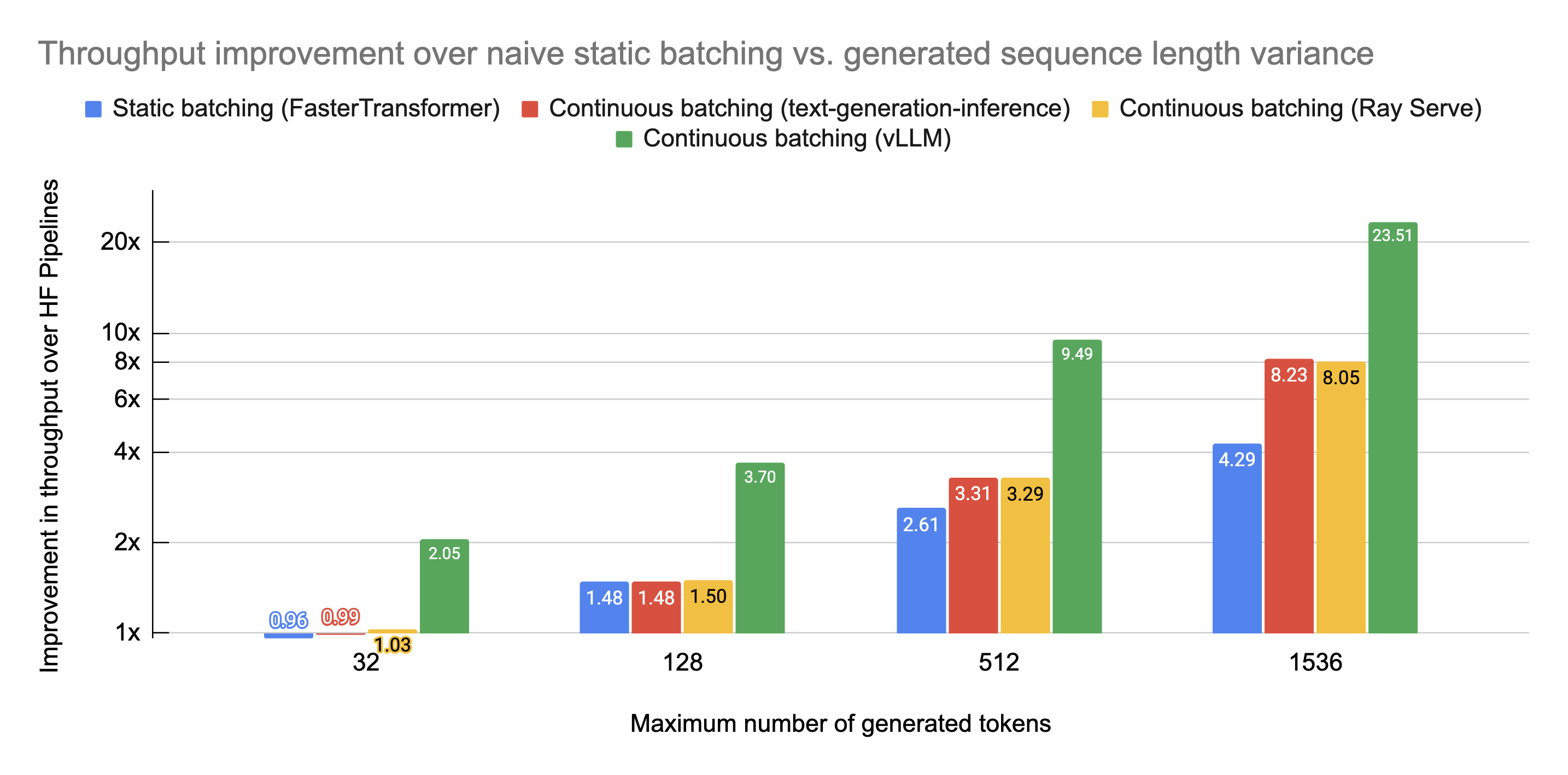
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
Key Concepts in Efficient LLM Inference | by Sebastian Pineda Arango ...
Efficient LLM Inference on CPUs | Springer Nature Link (formerly ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
LLM Inference-Time Computing: Enhancing LLM Reasoning and Accuracy ...
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
What is LLM Inference? • luminary.blog
Optimizing AI Performance: A Guide to Efficient LLM Deployment
How AI and Accelerated Computing Are Driving Energy Efficiency | NVIDIA ...
What is LLM Model Inference?
The Future of Serverless Inference for Large Language Models – Unite.AI
Rethinking LLM inference: Why developer AI needs a different approach
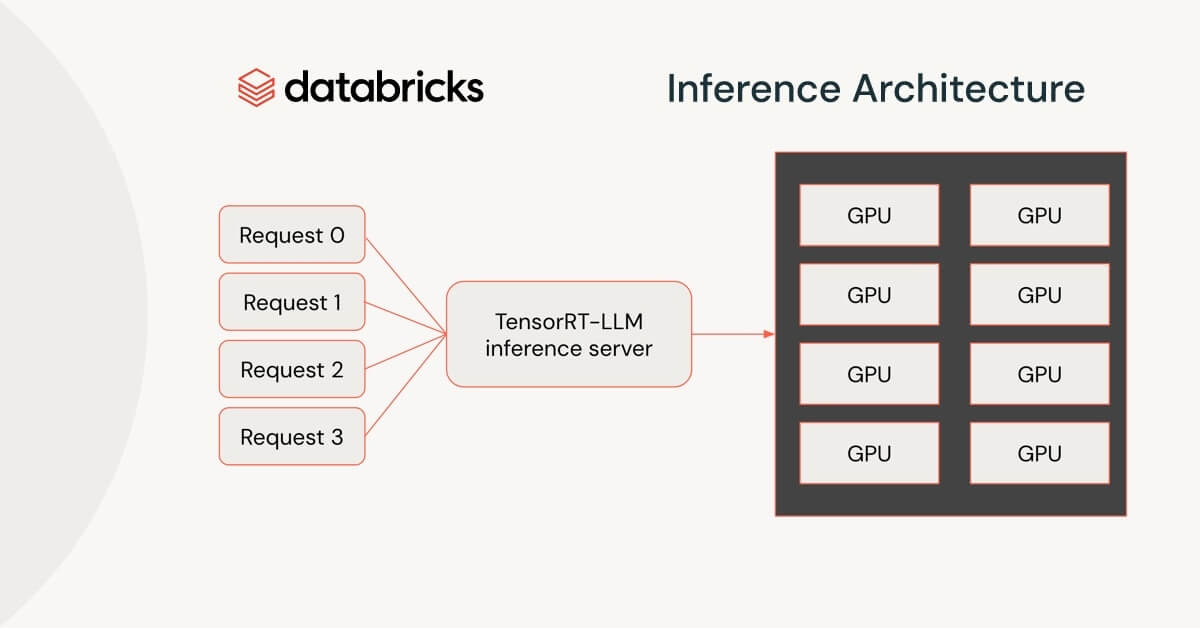
Integrating NVIDIA TensorRT-LLM with the Databricks Inference Stack ...
Unlocking the Power of LLM Inferencing: Real-Time AI Insights and Solutions
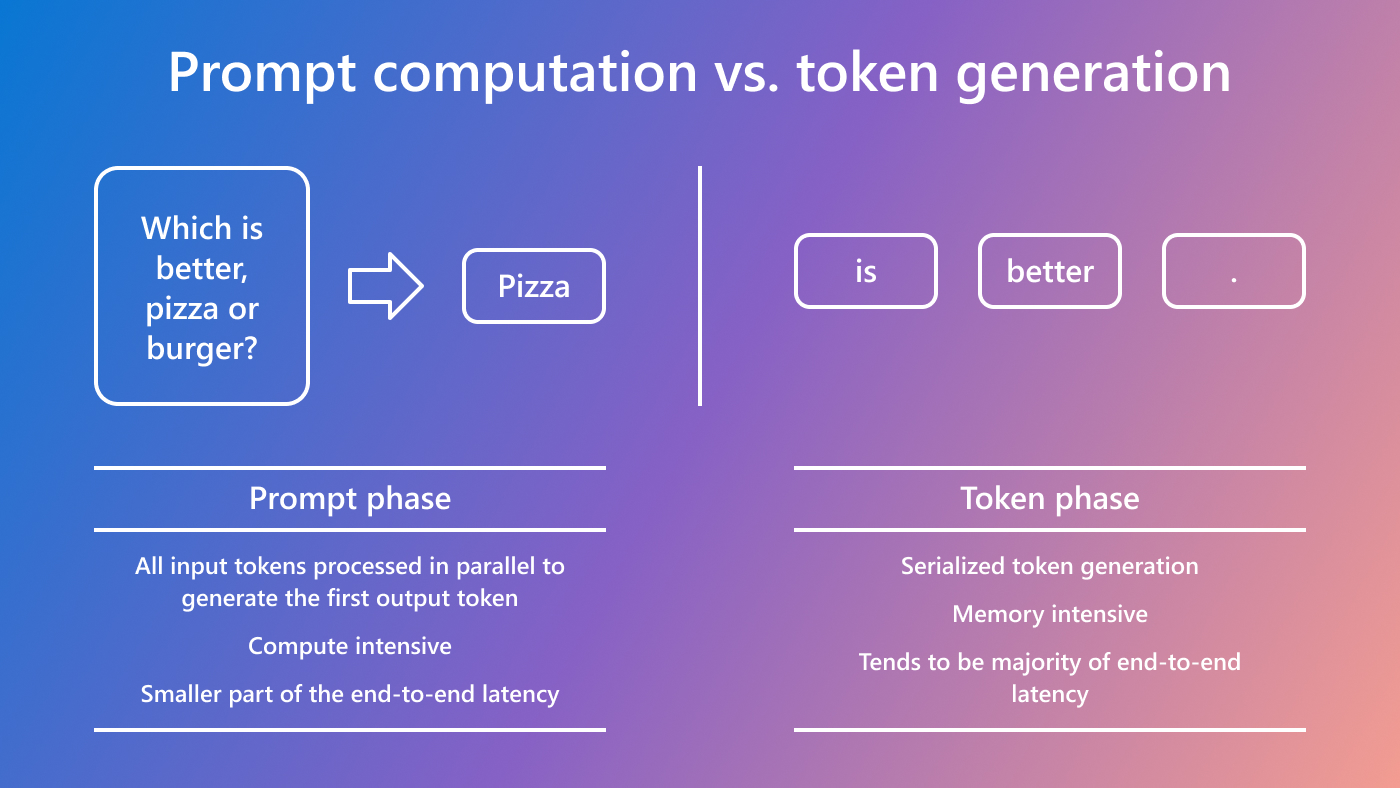
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
Understanding LLM Inference: How AI Generates Words | DataCamp
Understanding AI: LLM Basics for Investors
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Why Choose NVIDIA H100 SXM for Peak AI Performance
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer
GitHub - OpenCSGs/llm-inference: llm-inference is a platform for ...
Benchmarking de Inferência de LLM: Conceitos Fundamentais | Blog da NVIDIA
llm-inference · PyPI
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
Our Key Assumptions
Basic Understanding of Loss Functions and Evaluation Metrics in AI ...
图文详解LLM inference:LLM模型架构详解 - 知乎





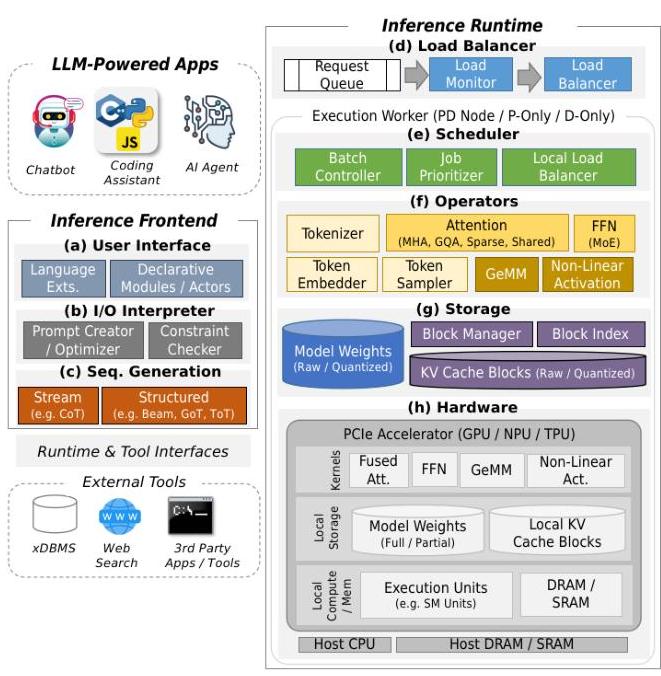
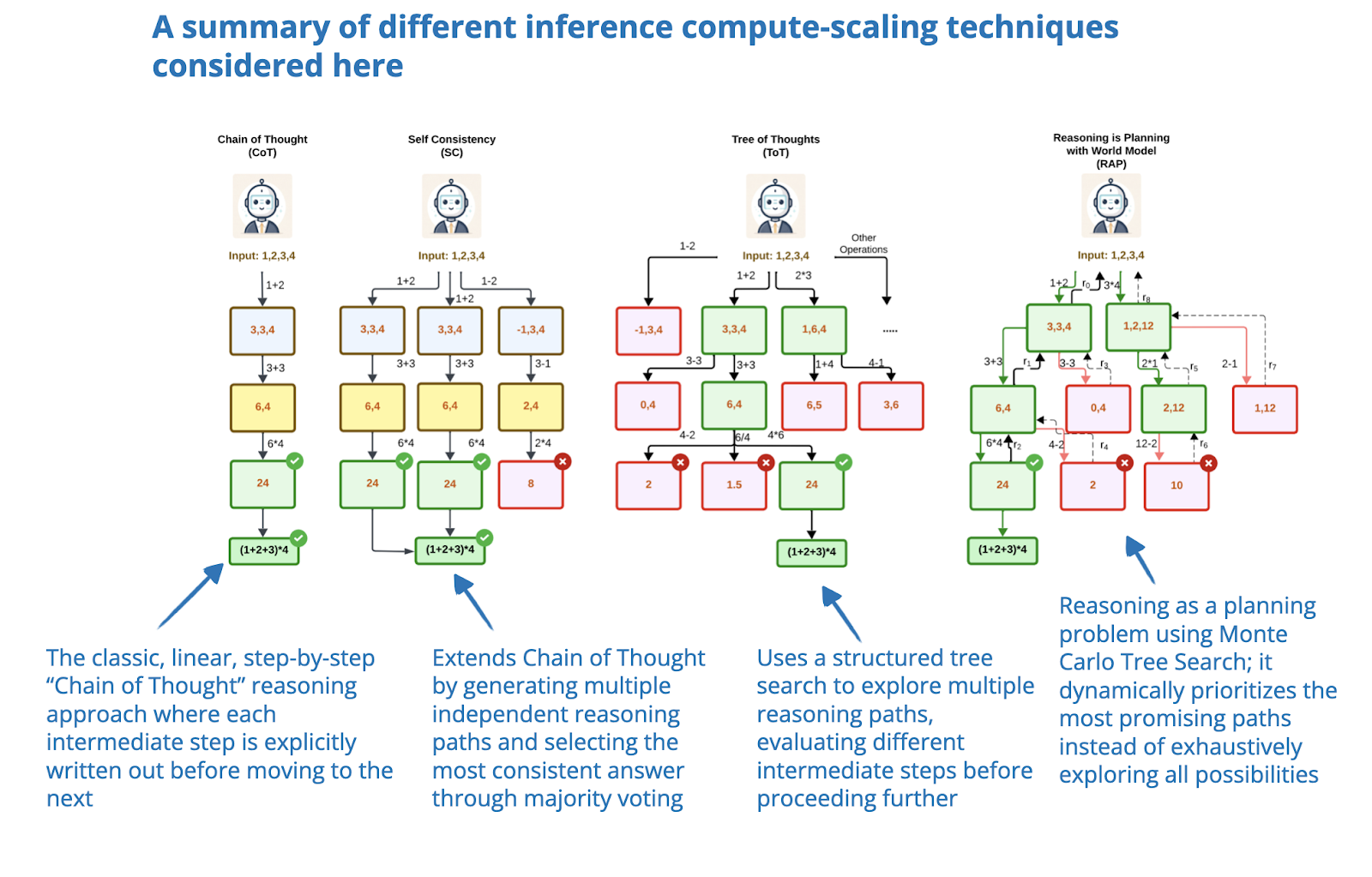
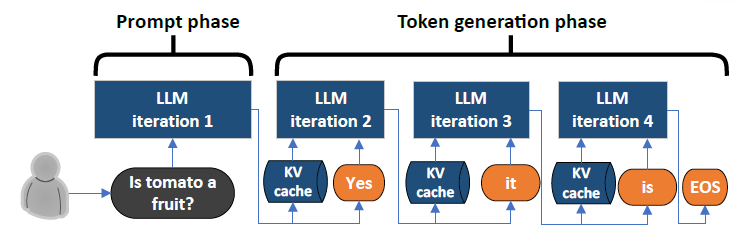

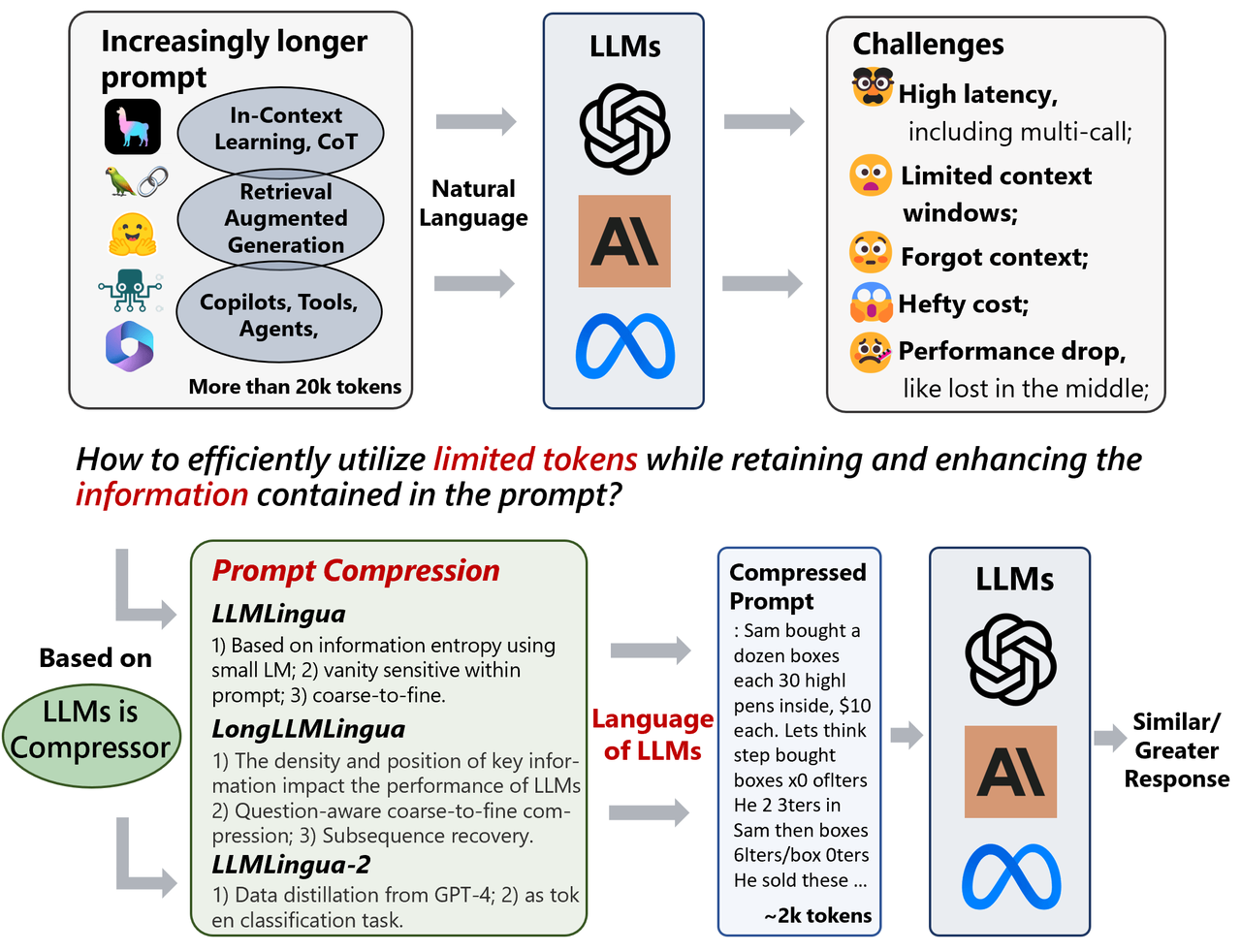
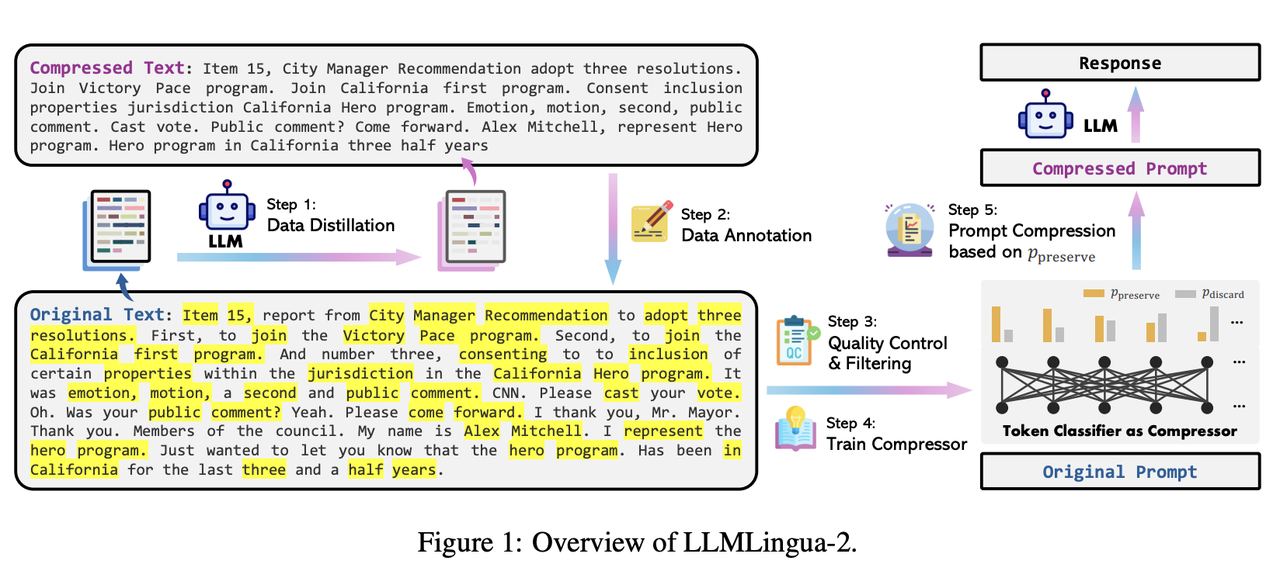
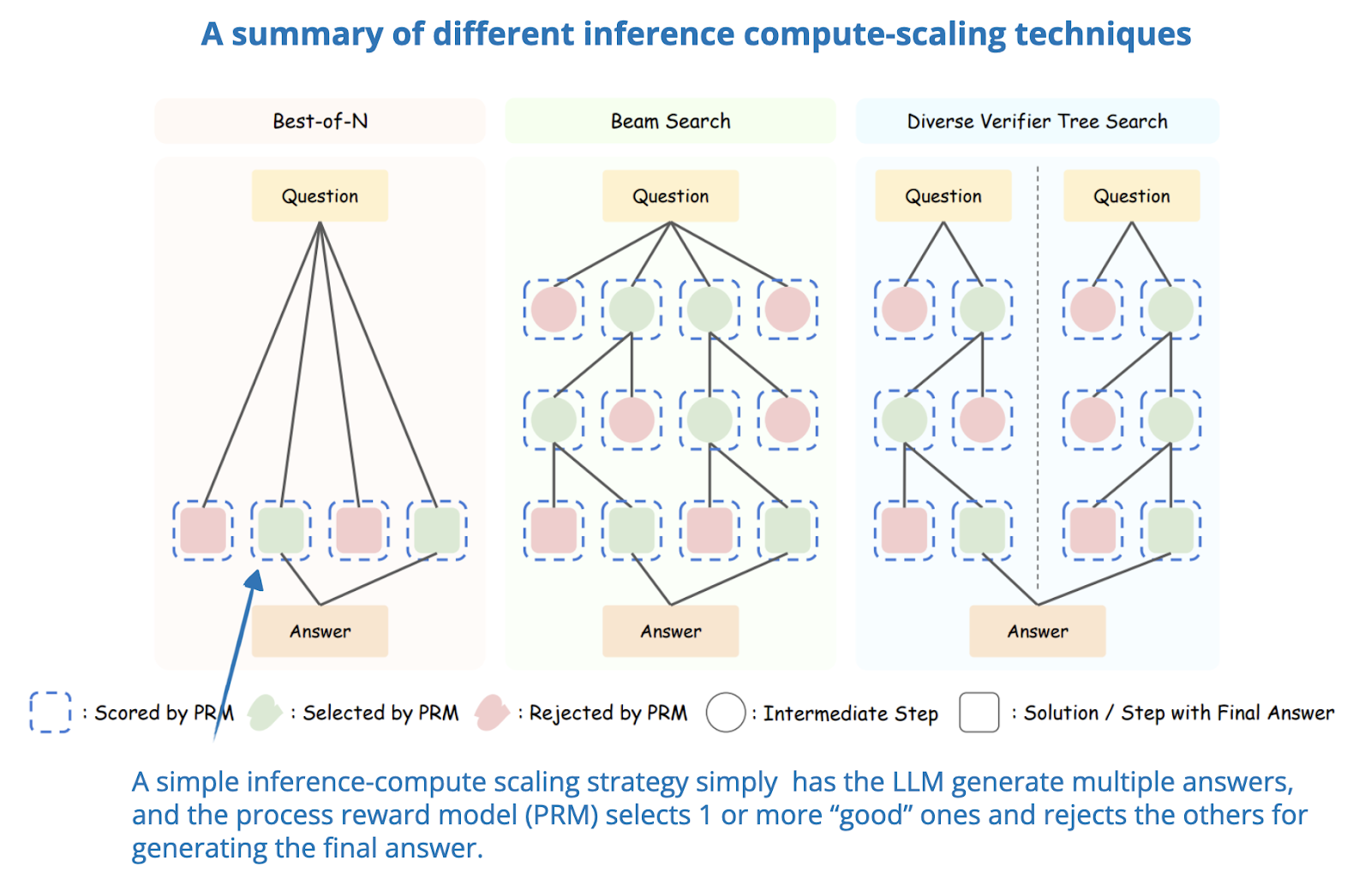
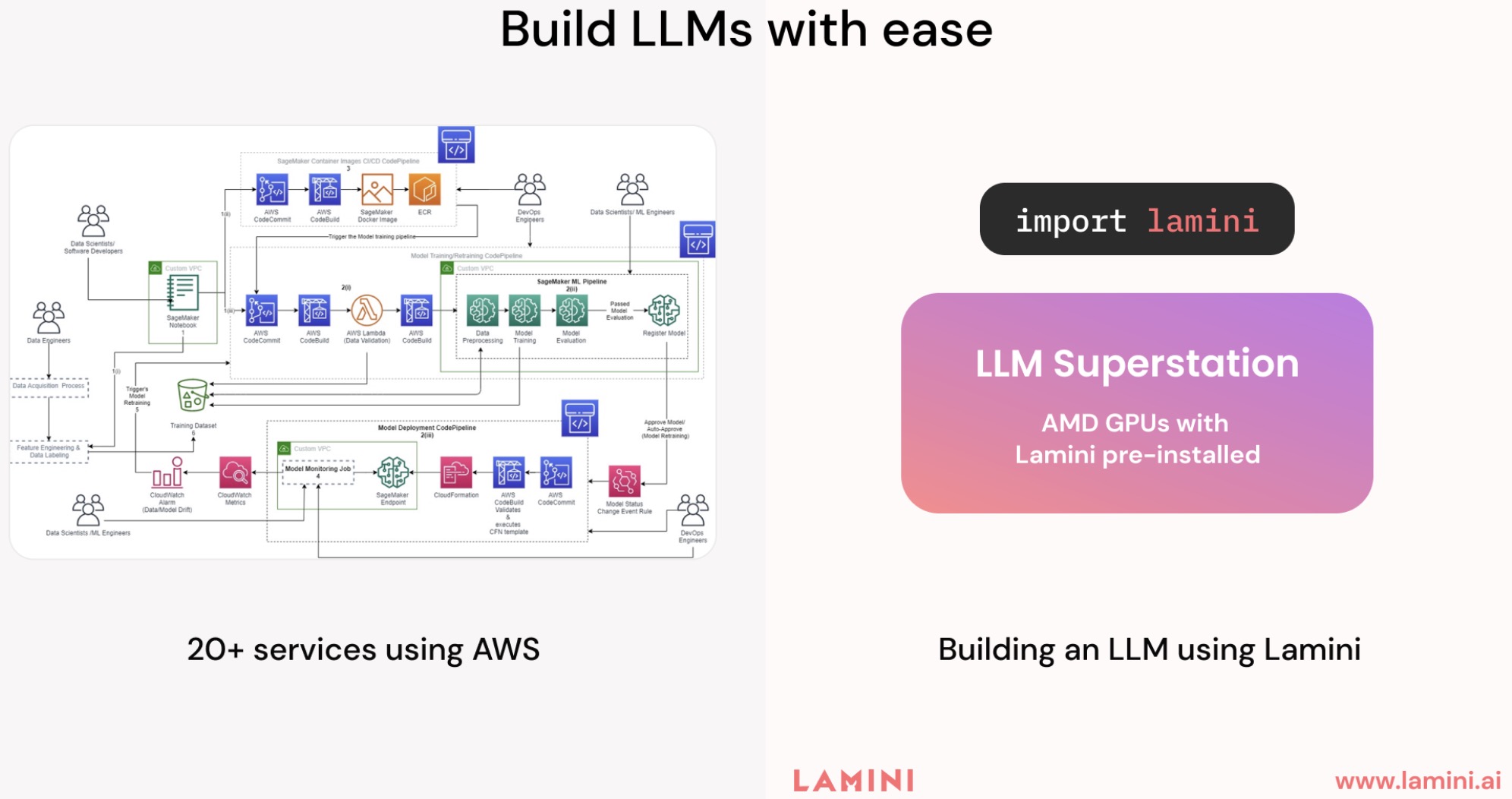


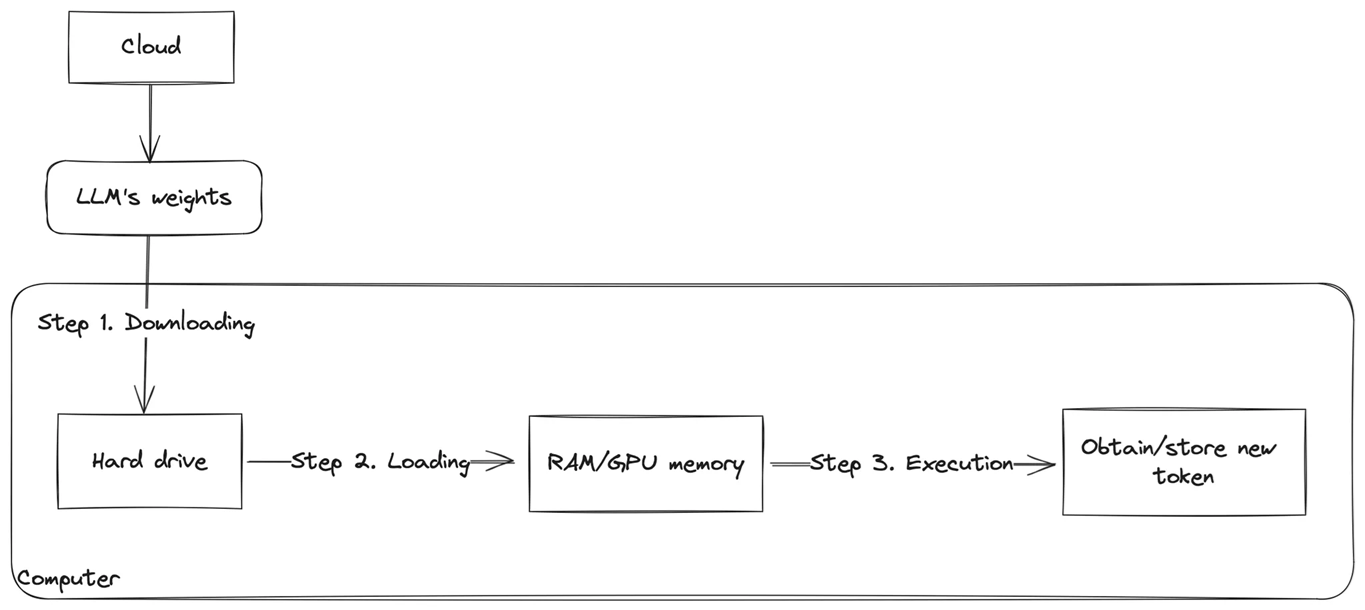
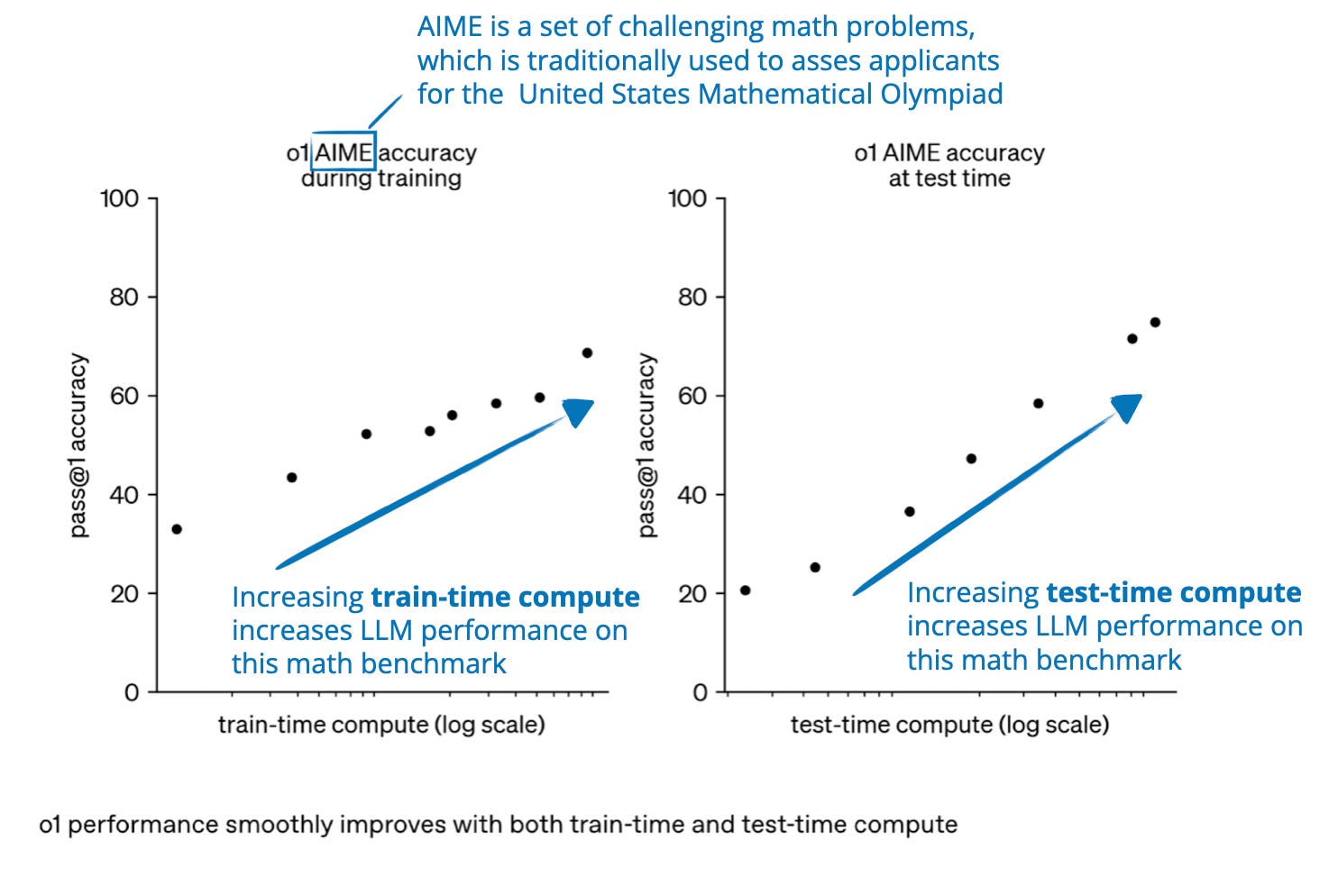












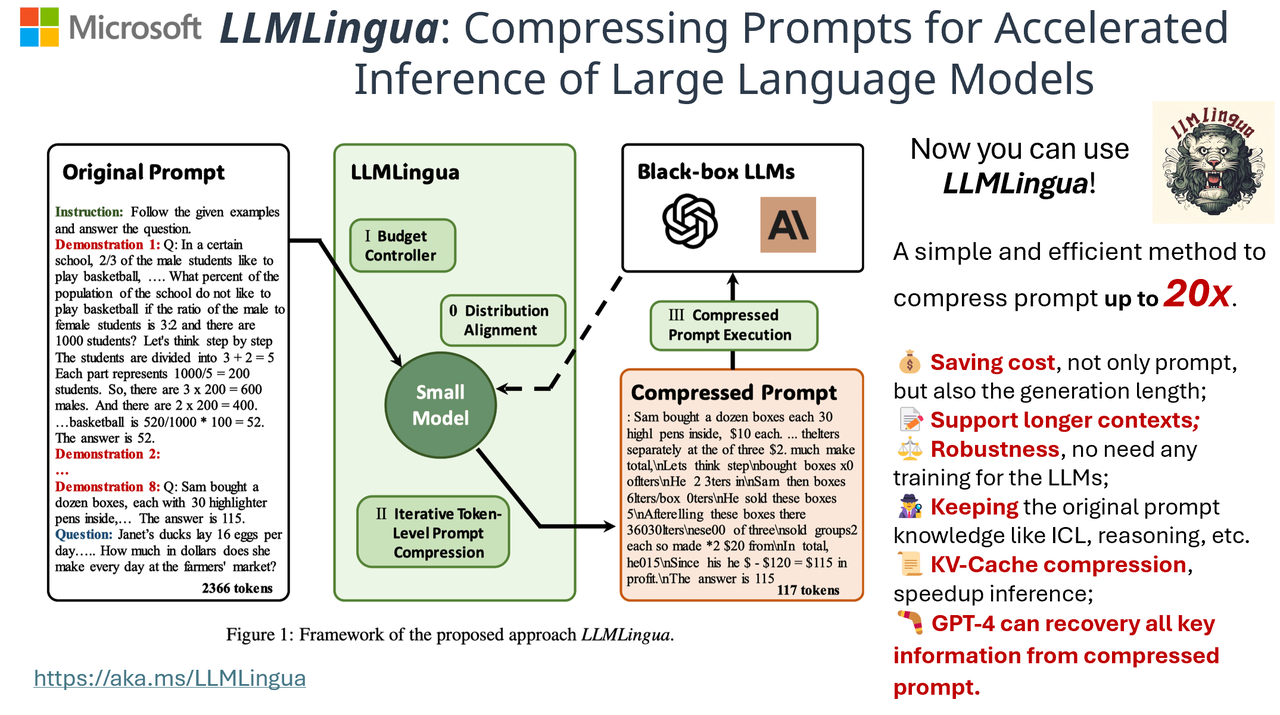
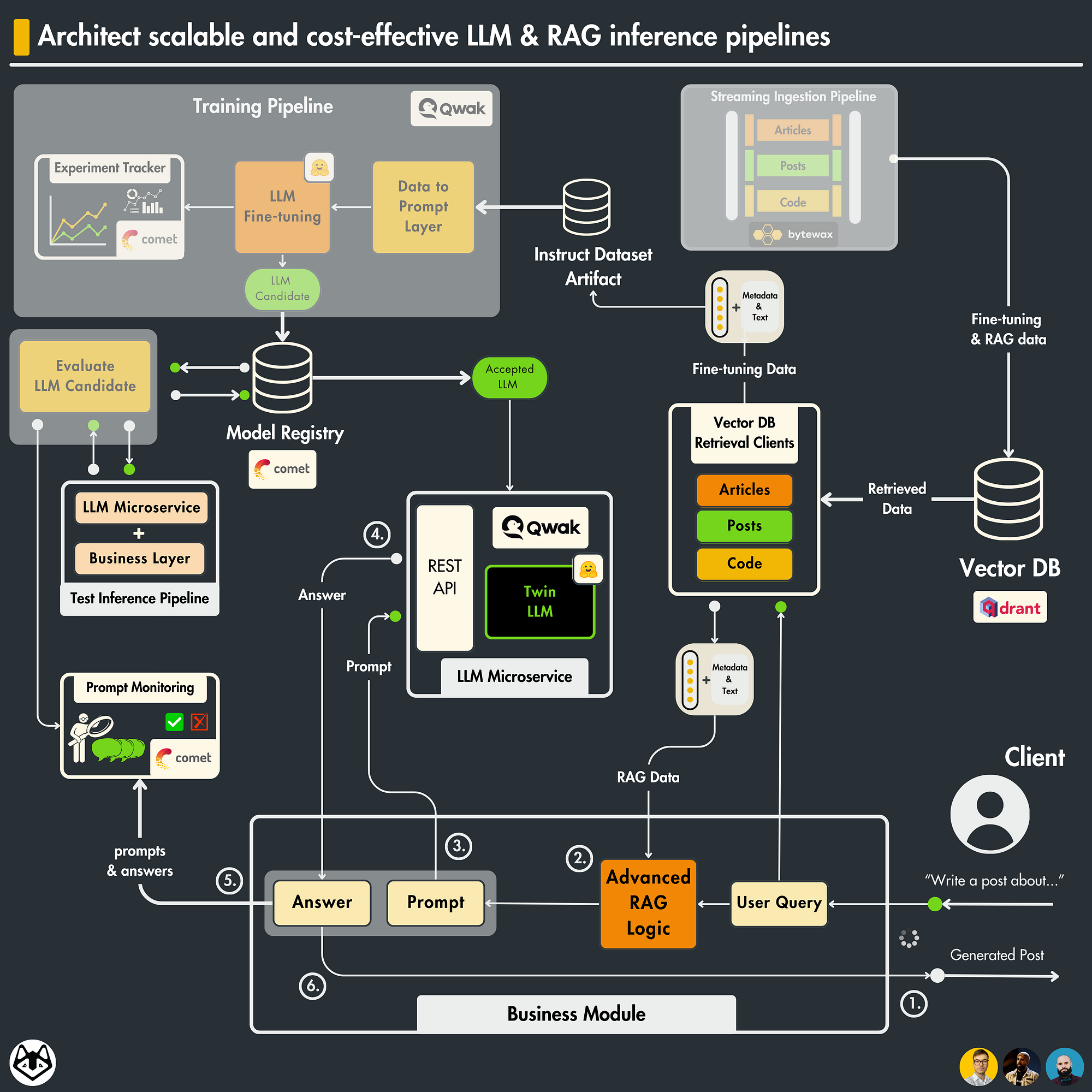

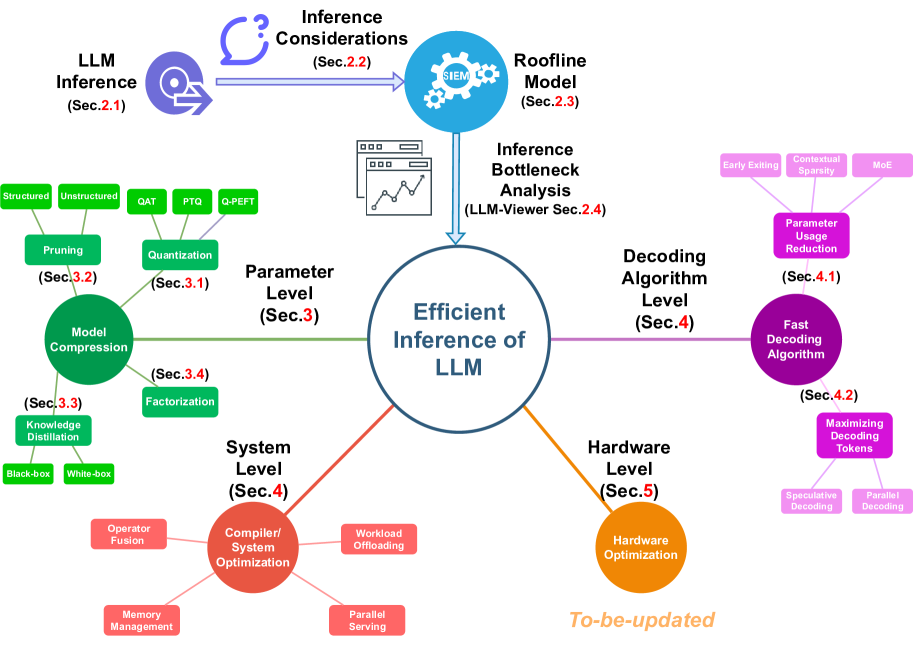
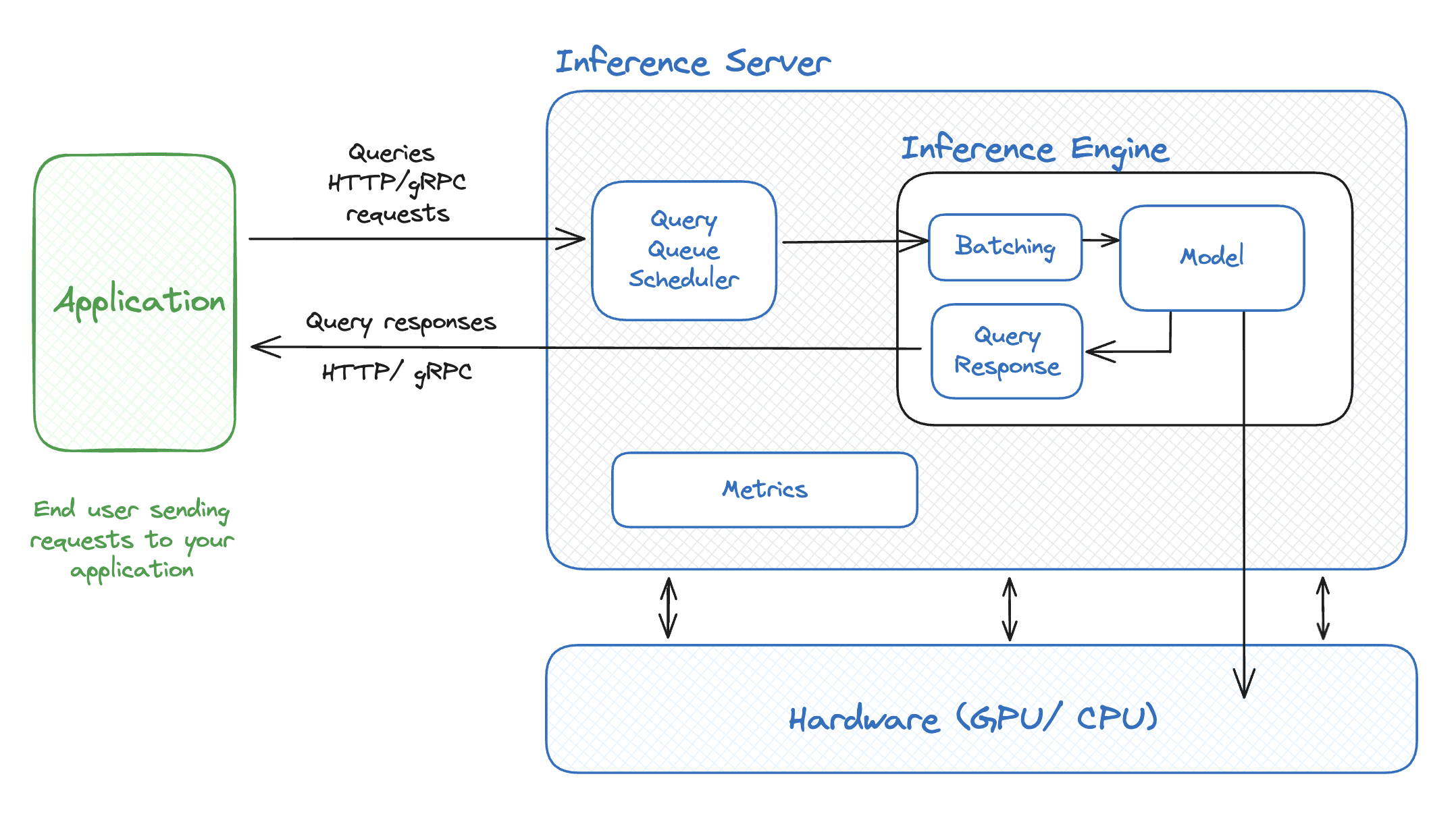



























.png)



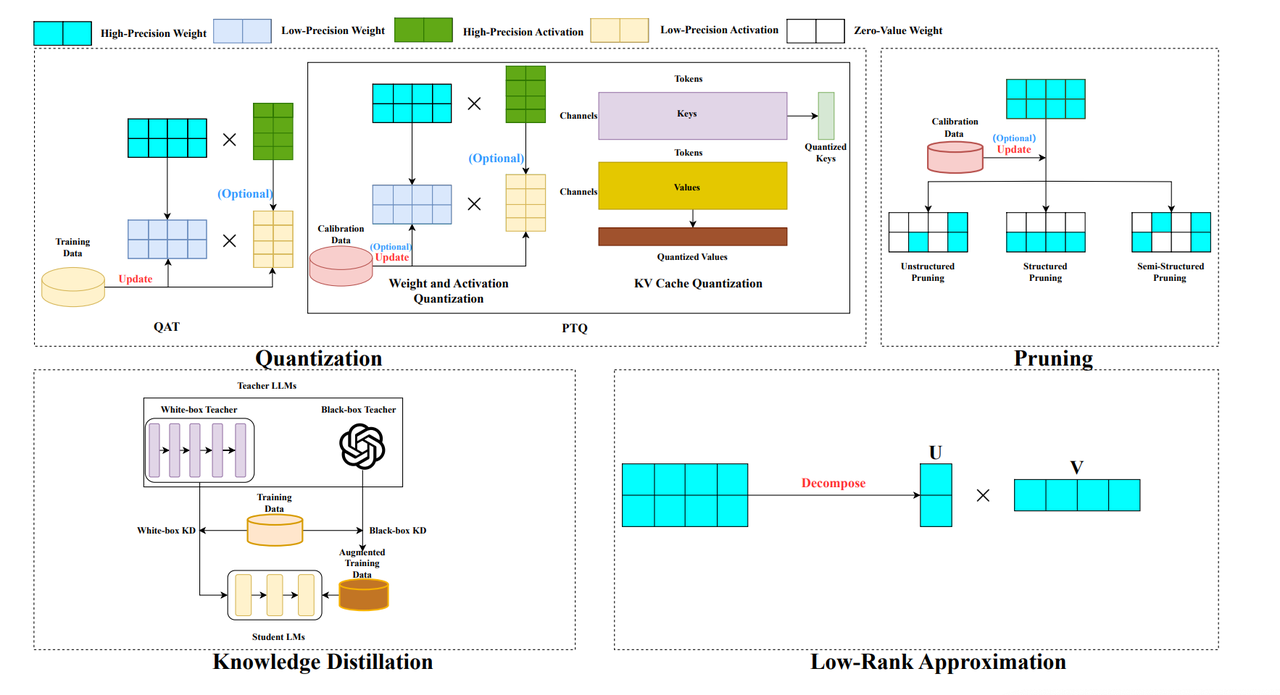
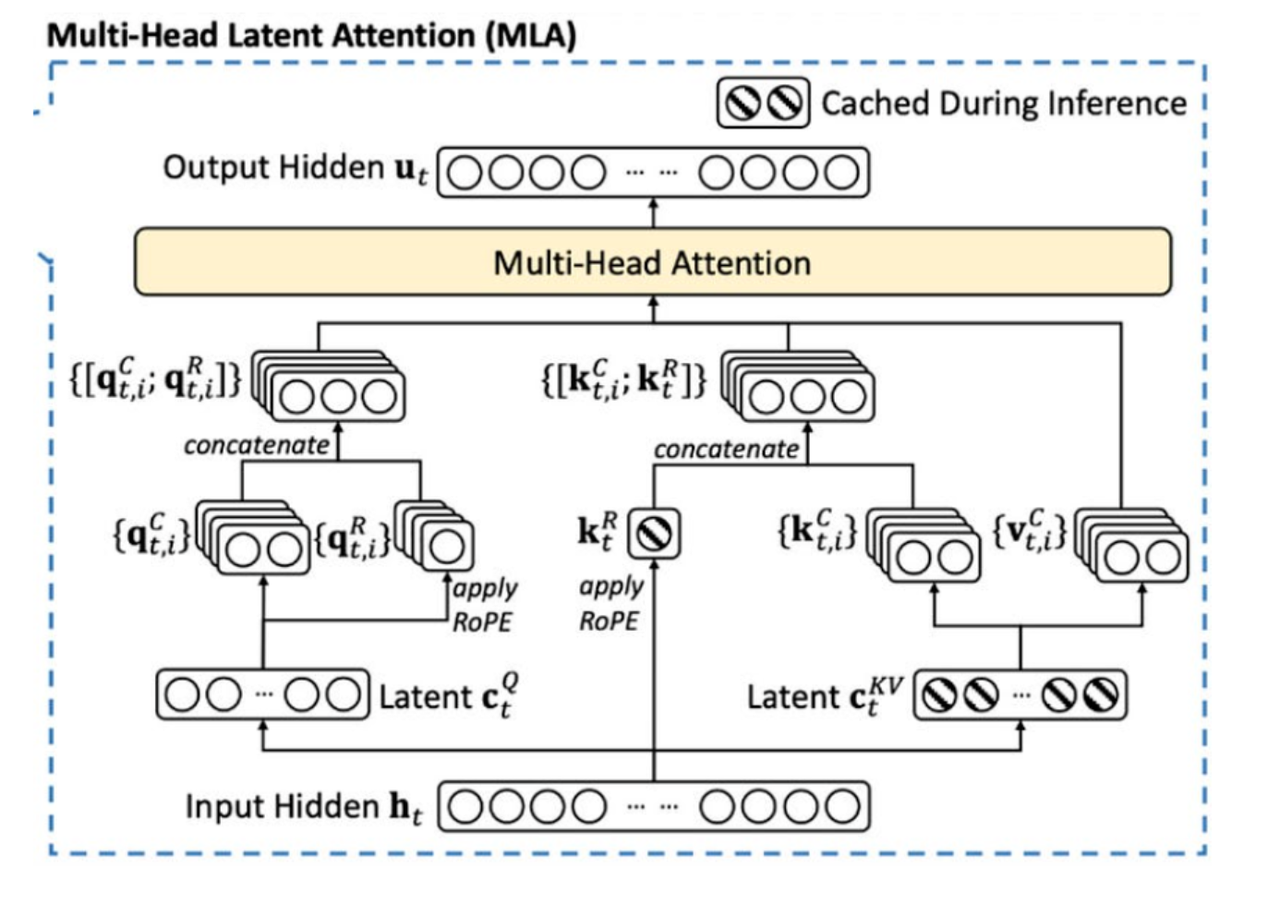
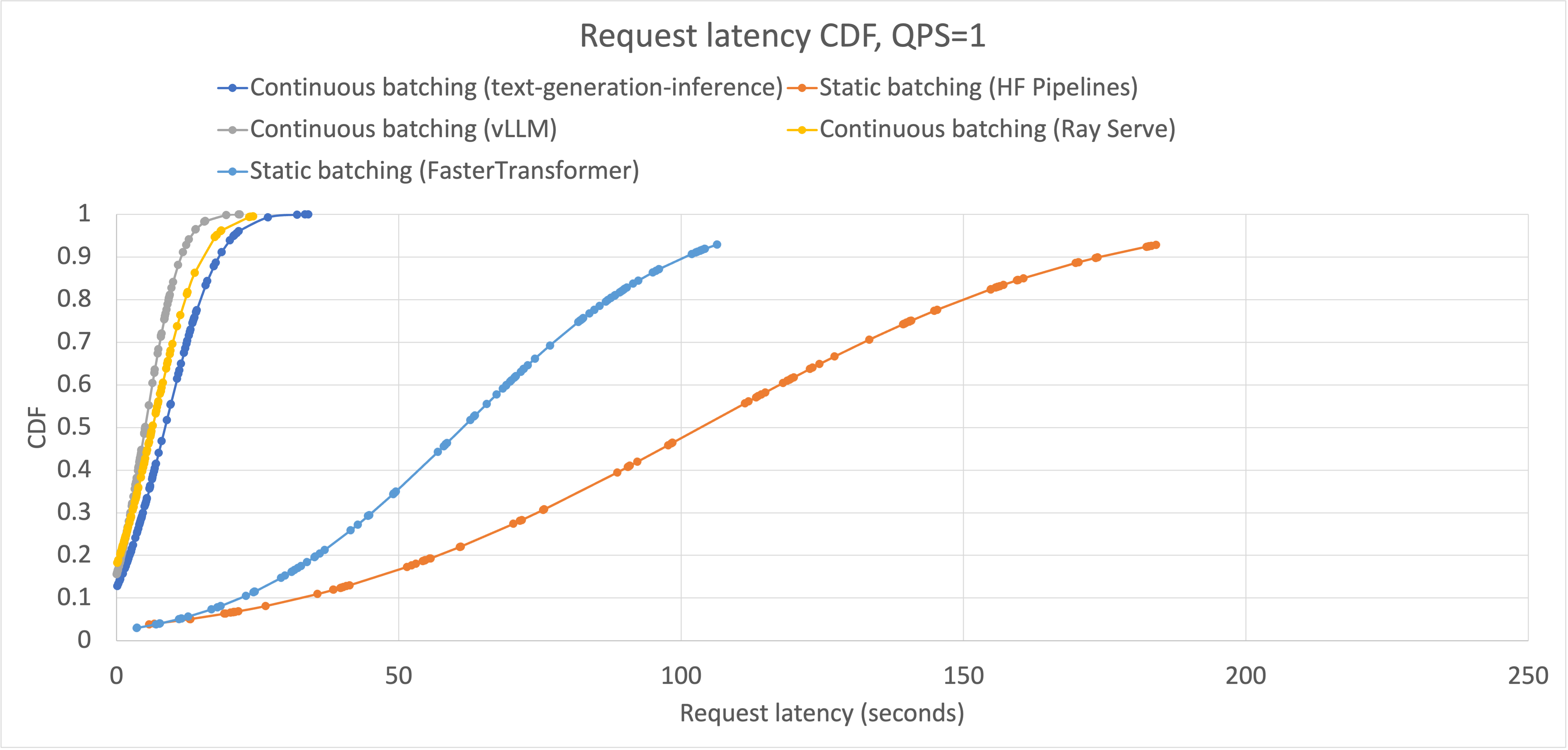
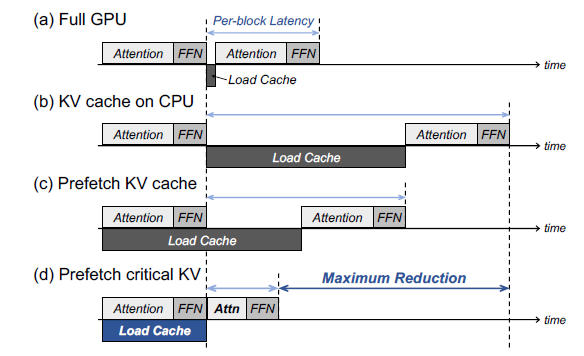
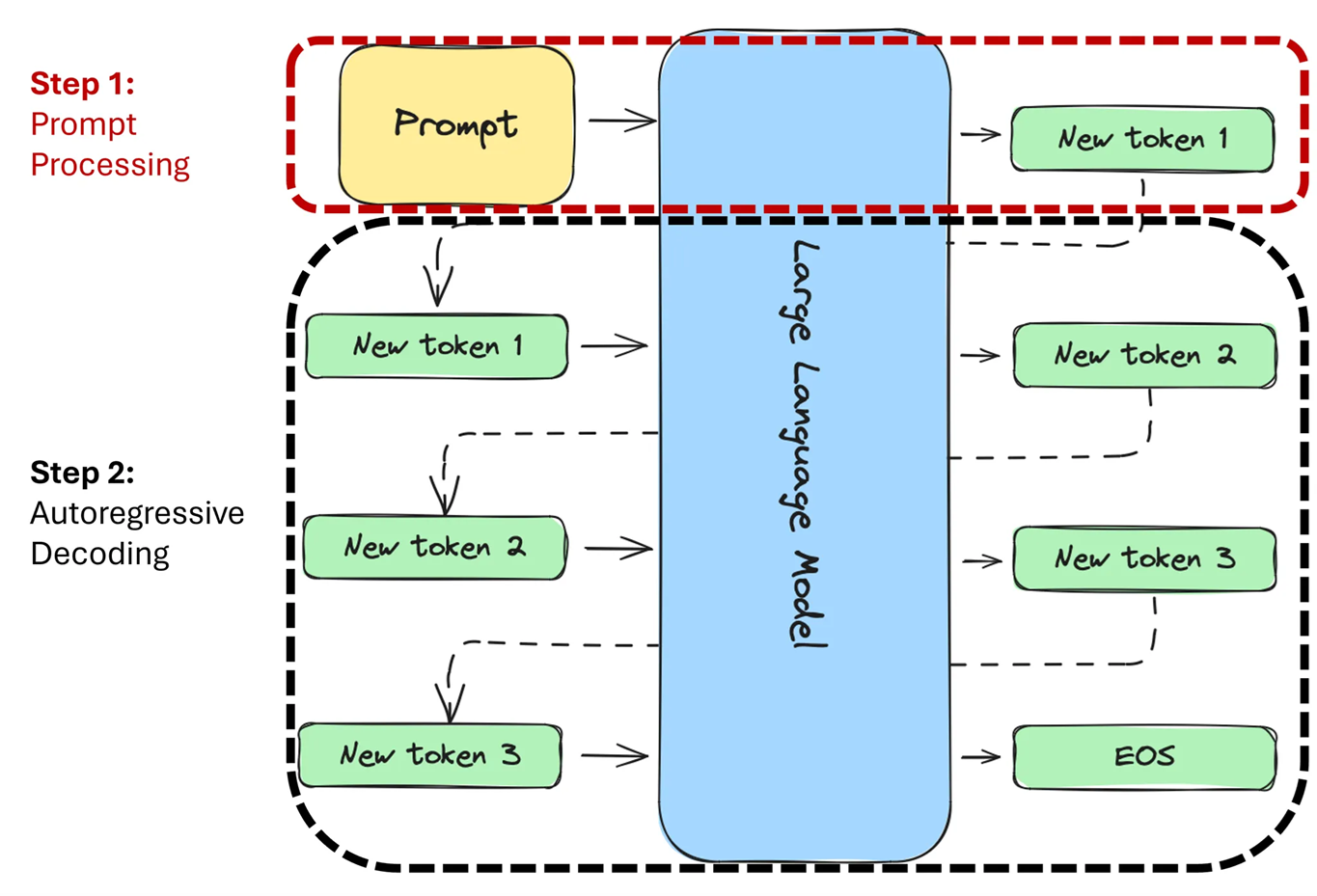

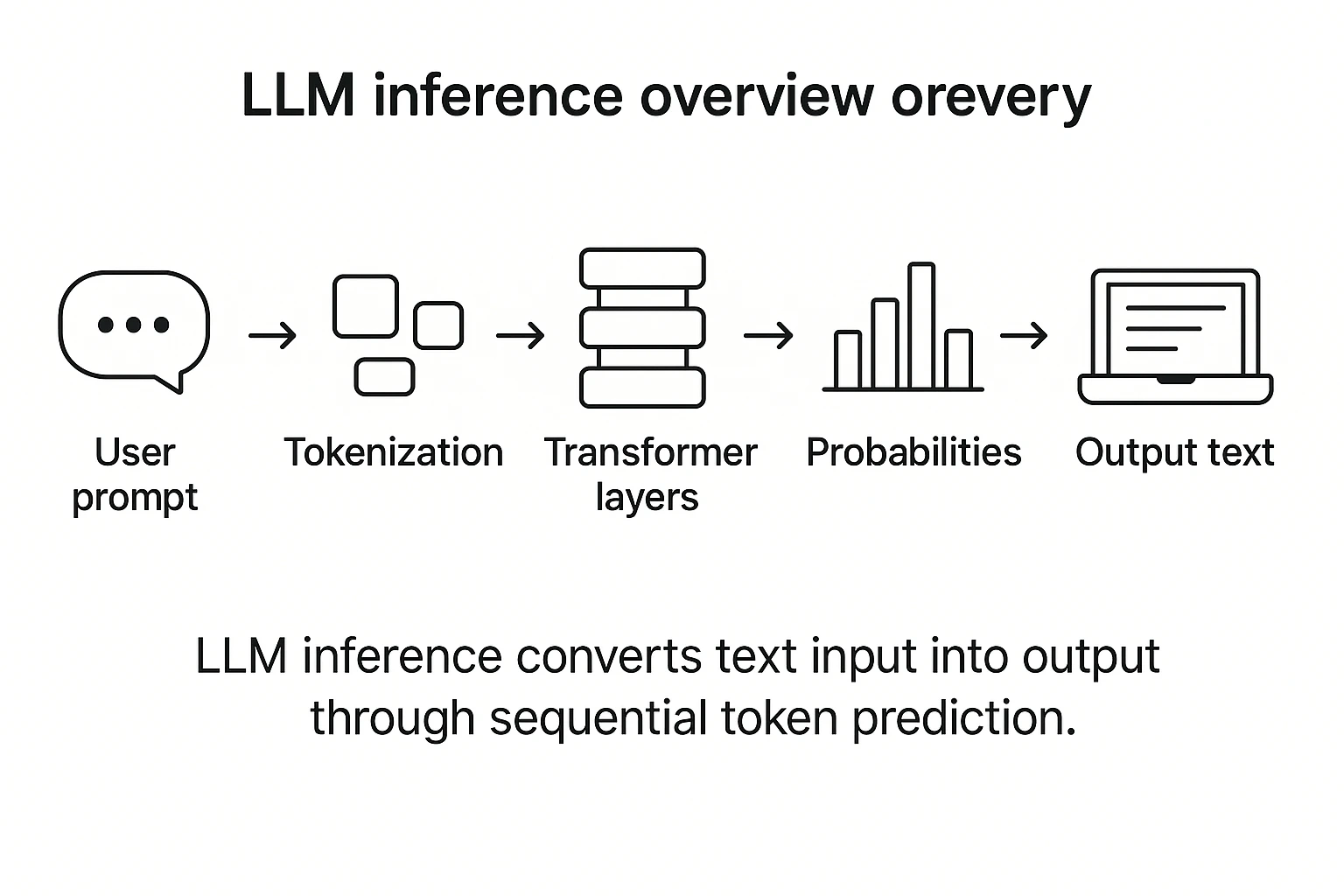





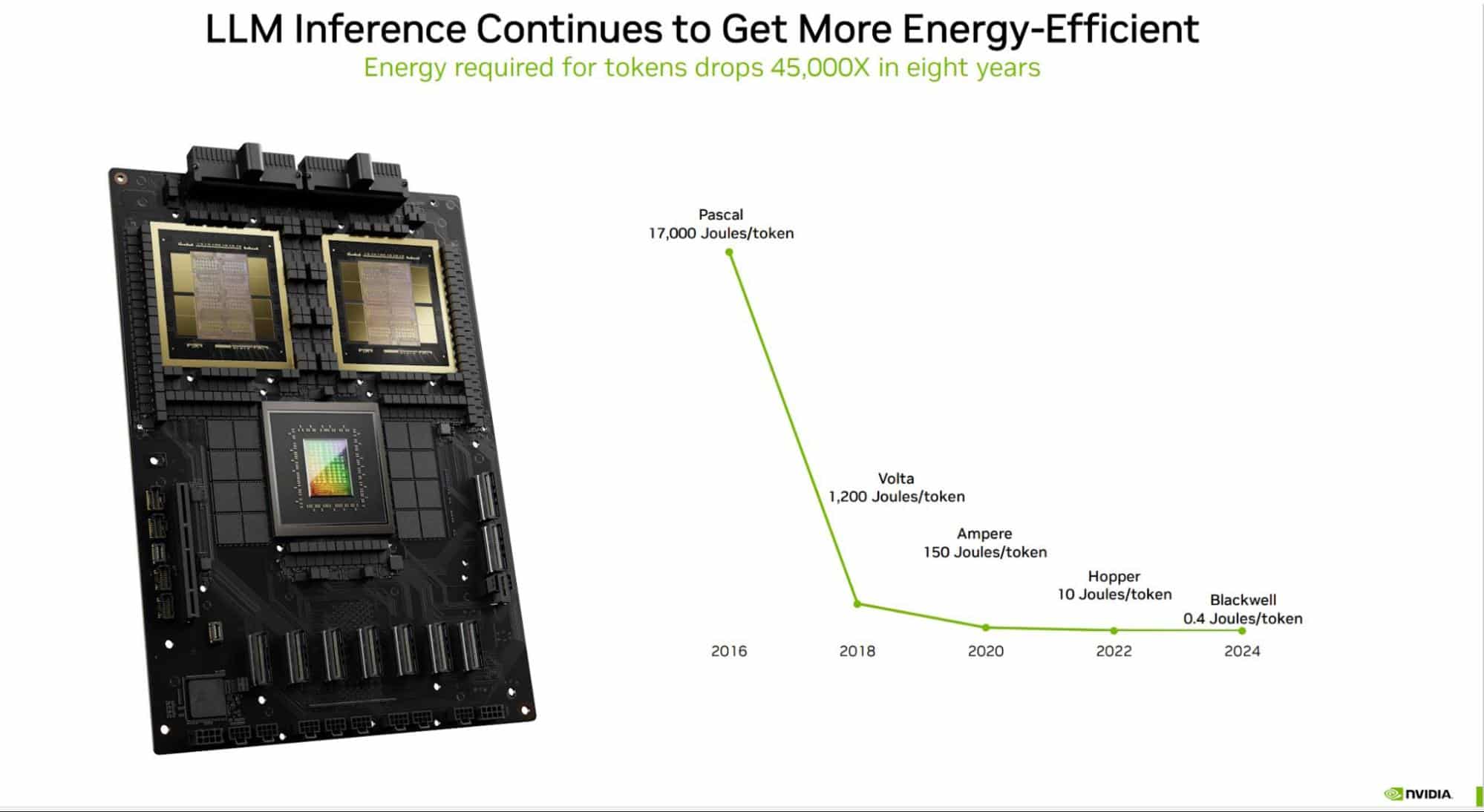

.png)
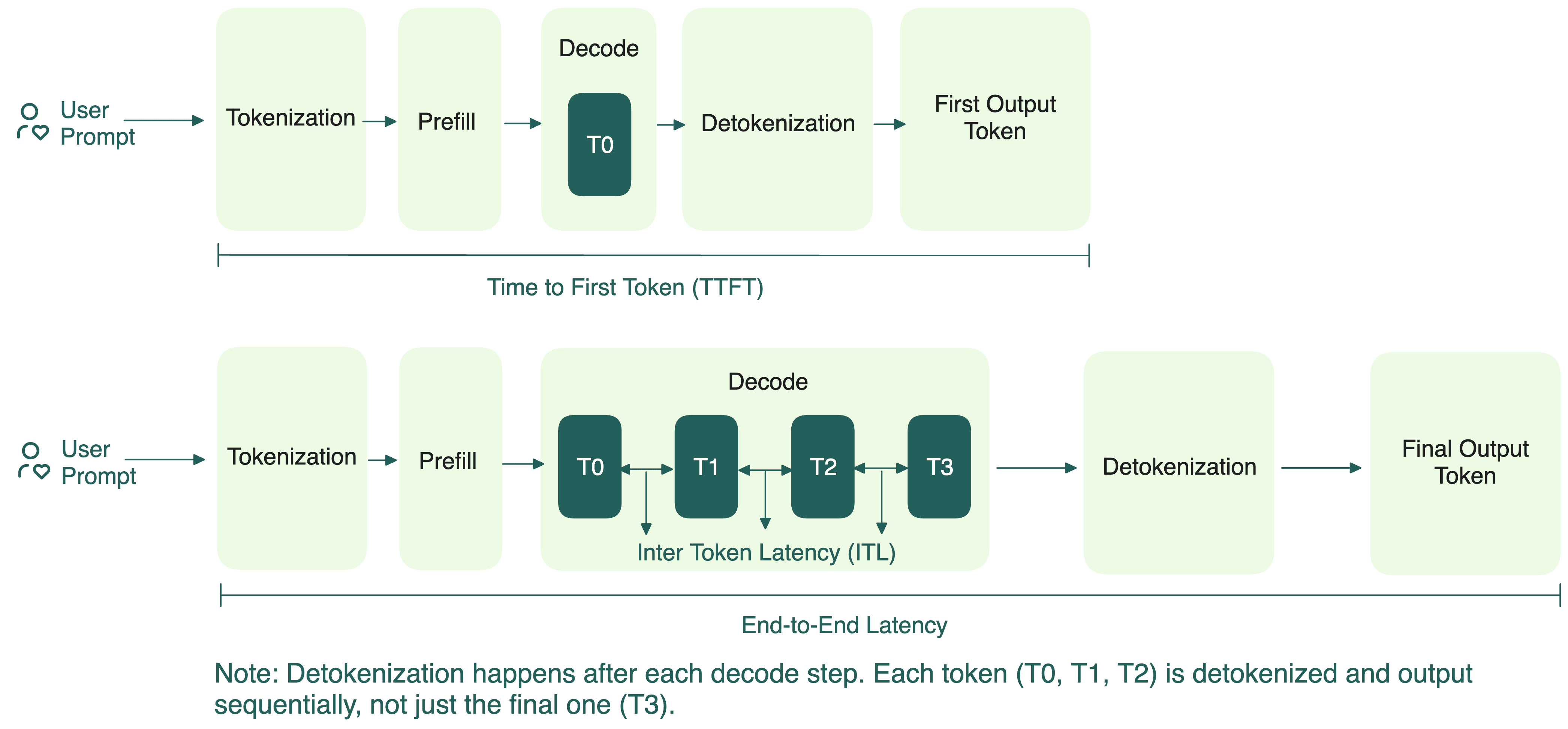





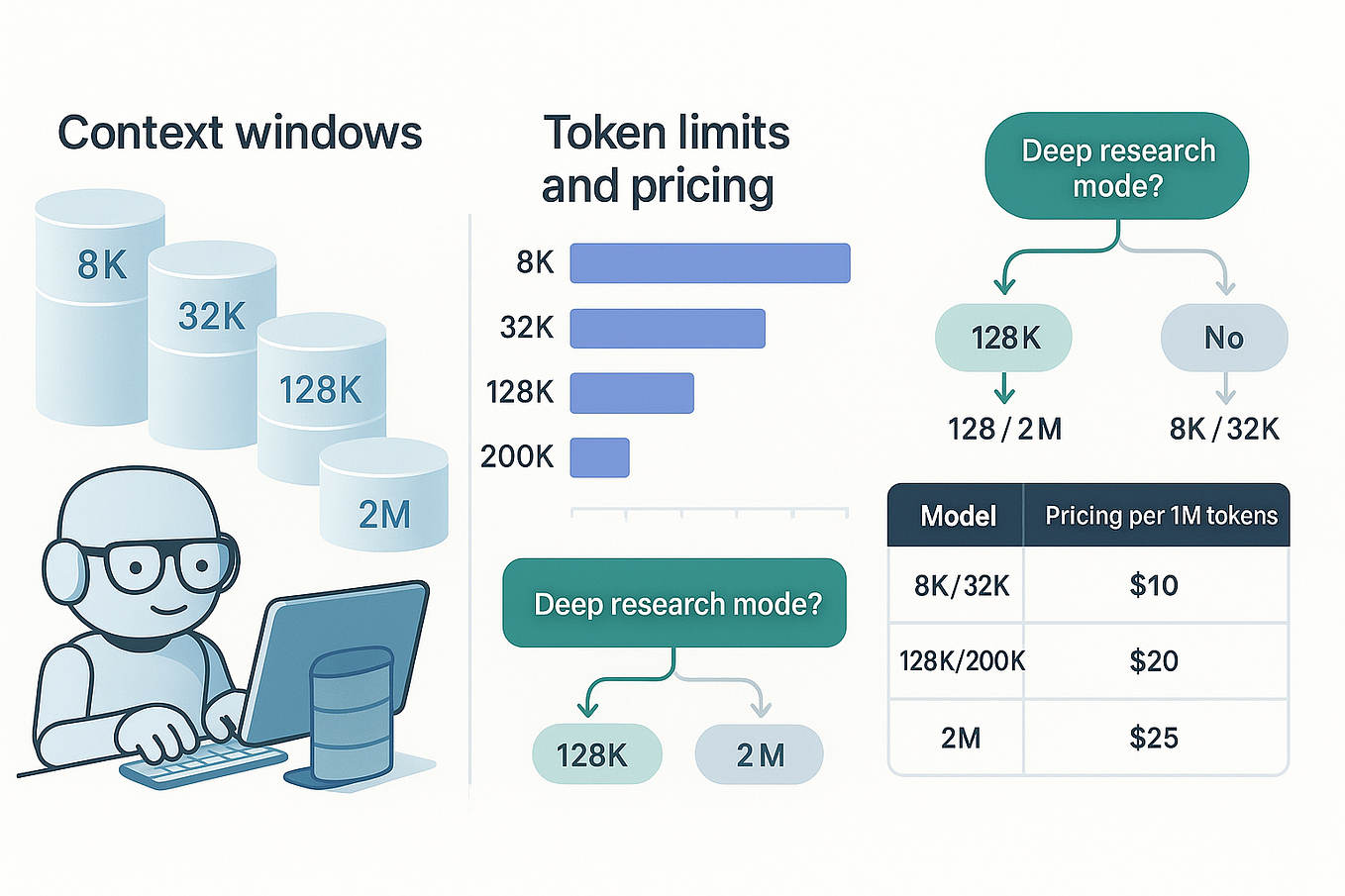
.png?width=1000&height=600&name=Challenges%20in%20LLM%20Training%20and%20AI%20Inference%20Infographics%20(1).png)
.png)

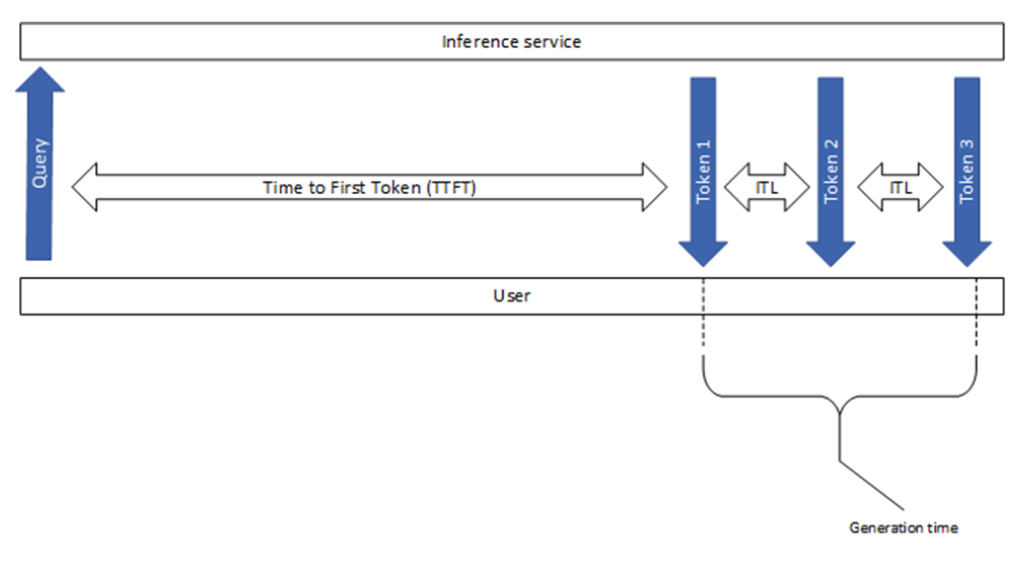

.png)